Ensembling Heterogeneous Models for Federated Learning

Federated learning trains a model on a centralized server using datasets distributed over a large number of edge devices. Applying federated learning ensures data privacy because it does not transfer local data from edge devices to the server. Existing federated learning algorithms assume that all deployed models share the same structure. However, it is often infeasible to distribute the same model to every edge device because of hardware limitations such as computing performance and storage space. This paper proposes a novel federated learning algorithm to aggregate information from multiple heterogeneous models. The proposed method uses weighted average ensemble to combine the outputs from each model. The weight for the ensemble is optimized using black box optimization methods. We evaluated the proposed method using diverse models and datasets and found that it can achieve comparable performance to conventional training using centralized datasets.
Methodology
The basic idea behind the proposed method is to ensemble the heterogeneous models. Naively applying FedSGD or FedAVG is not possible since there does not exist any obvious mapping between parameters in different models. Therefore, we employ weighted average because simple average or majority voting combines all models equally and results in suboptimal performance if the local training datasets distributed across the edge devices are biased.
The optimizer is responsible for tuning weight of each model such that the accuracy of the ensembled model is maximized. In this work, we consider and compare six well-known black box optimization algorithms:
- Grid Search (GS)
- Random Search (RS)
- Particle Swarm Optimization (PSO)
- Bayesian Search (BS)
- Tree Parzen Estimator (TPE)
- Sequential Model-based Algorithm Configuration (SMAC)
Evaluation
We simulated 1,200 edge devices in all setups. In a communication round, 1,000 devices are randomly selected to participate in the federated learning. Each edge device performs 10 local epochs in a communication round and sends its update local model to the server. The server updates the global model and broadcasts the new model to the edge devices. We perform 10 communication rounds in all experiments. Thus, the local batch size is 4 (4 images × 10 communication rounds). Once the FedAVG step is complete, the optimization step is performed for 50 trials.
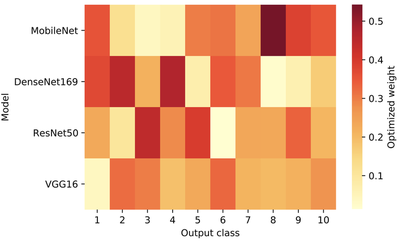
The weights to average the heterogeneous models optimized using the proposed method in the experimental setup C (MobileNet, DenseNet169, ResNet50 and VGG16) with the CIFAR-10 dataset as shown in above figure. For the same output class, models with darker cells are weighted heavier than the models with lighter cells. This figure clearly reveals that the optimized weight for each output class and each heterogeneous model is different. Taking the 8th output class as an example, MobileNet has the highest weight while DenseNet169 has the lowest weight. This suggests that MobileNet is able to identify the 8th class more accurately than DenseNet169. In this manner, models that achieve higher accuracy on a particular class will have higher weights assigned to them after the weight optimization.
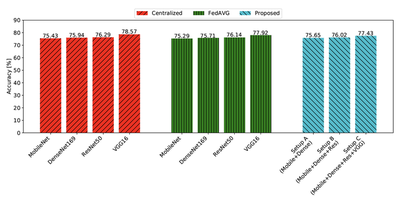
The above figure shows the comparison of accuracy. The accuracy of the proposed method in setup A, which combines MobiletNet and DenseNet169, is 75.65%. In FedAVG, MobiletNet and DenseNet169 achieve 75.29% and 75.71%, respectively. This suggests that the proposed method is able to effectively combine its constituent heterogeneous models without significant overhead in terms of accuracy. Furthermore, MobiletNet and DenseNet169 trained with a centralized dataset each reach 75.43% and 75.94% accuracy, which is very close to FedAVG and the proposed method. Thus we can conclude that the overhead of federated learning is minimal.
In this work, we proposed a novel federated learning algorithm for neural network models with heterogeneous structures. The proposed method utilizes weighted average ensemble to combine the outputs from different models. Black box optimization is used to tune the weights for the output classes of each model. We compared six black box optimization algorithms and found that TPE was able to achieve the highest accuracy. However, TPE took the longest runtime among the six methods. As a future work, we will enhance the proposed method to regression and localization tasks. In addition, other parameter optimization techniques and federated learning algorithms will be investigated.
Publication
- K. Thonglek, K. Takahashi, K. Ichikawa, C. Nakasan, H. Iida, “Federated Learning of Neural Network Models with Heterogeneous Structures”, 19th International Conference on Machine Learning and Applications (ICMLA 2020), Dec. 2020.
Kundjanasith Thonglek (Tem)
Dotoral Student
Doctoral student at Information Science, Nara Institute of Science and Technology, Japan