A Study on Automatic Parallelization with OpenMP using Large Language Model
 The Overview of the Proposed Automatic Parallelization with OpenMP using LLM
The Overview of the Proposed Automatic Parallelization with OpenMP using LLMTo fully utilize multi-core processors, the development of parallel programs is essential. However, creating parallel programs is a challenging and complex task. Automatic parallelization techniques have been extensively studied to simplify this process by transforming sequential code into parallel code automatically. Most existing automatic parallelization tools rely on static analysis, which can identify certain types of parallel structures but fails to detect others, resulting in suboptimal performance gains.
In contrast, the recent emergence of Large Language Models (LLMs) in the field of Natural Language Processing (NLP) has inspired software engineering researchers to adopt these models. LLMs have demonstrated state-of-the-art performance across a wide range of tasks. Building on these advancements, this study proposes an automatic parallelization tool based on LLMs. To replicate the functionality of existing automatic parallelization tools, two models are developed: the first model classifies parallelizable for-loops, and the second model generates OpenMP directives. Datasets are collected from two sources—Google BigQuery public datasets and GitHub public repositories—and pre-processed to enhance the quality of OpenMP source code. These datasets are then utilized for downstream tasks by fine-tuning CodeT5/CodeT5+, one of the Code LLM models.
Design and Implementation
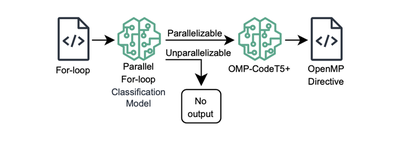
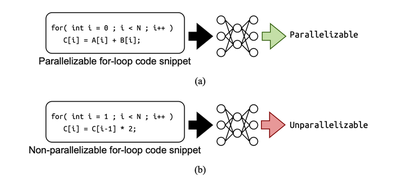

To replicate the functionality of automatic parallelization tools, we developed two models: the Parallelizable For-loop Classification Model [1,3], which detects whether a given for-loop is parallelizable, and the OpenMP Directive Generation Model [2], also referred to as OMP-CodeT5+, which generates OpenMP directives for parallelizable for-loops identified by the classification model.
To train these models for tasks related to parallel programming, we required a parallel source code dataset. However, at the time of development, no publicly available parallel source code dataset existed. Therefore, we gathered and created our own dataset from public GitHub repositories containing source code that utilizes OpenMP. Both models were trained on this dataset, with slightly different preprocessing steps tailored to the requirements of each model.
We fine-tuned the CodeT5/CodeT5+ family—one of the state-of-the-art Code LLMs at the time of development—as a pre-trained model to develop downstream tasks for classification and generation. The CodeT5/CodeT5+ family has been trained on C/C++ source code, making it particularly well-suited for our goal of parallelizing C/C++ source code using OpenMP.
Evaluation
We evaluated the model using the NAS Parallel Benchmarks Suite (NPB). NPB consists of eight benchmarks: Embarrassingly Parallel (EP), Multi-Grid (MG), Conjugate Gradient (CG), discrete 3D Fast Fourier Transform (FT), Integer Sort (IS), Block Tri-diagonal Solver (BT), Scalar Penta-diagonal Solver (SP), and Lower-Upper Gauss-Seidel Solver (LU). The performance was compared with automatic parallelization techniques from Intel and AutoPar-Clava, which are widely recognized state-of-the-art methods.
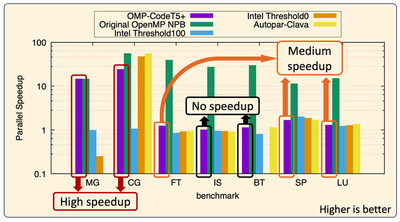
The results are categorized into three groups: high speedup, medium speedup, and no speedup, with one benchmark excluded. The EP source code contains only one parallel for-loop, and neither the trained model nor the baseline techniques succeeded in generating error-free OpenMP directives for this loop.
The accuracy of the classification model and the performance gains from parallelizing the source code using the generation model are influenced by the complexity of the for-loops. Larger for-loops tend to have greater complexity. For instance, the MG and CG source codes predominantly contain small for-loops, resulting in higher performance gains. Conversely, the IS and BT source codes feature larger for-loops, which the trained models struggled to parallelize correctly.
Future Work
In the future, the pre-processed training data should incorporate more contextual information from the input source code to enhance the model’s capability to identify and generate parallel source code. Furthermore, the training dataset must be significantly expanded to effectively handle highly complex source codes.
Publications
- Soratouch Pornmaneerattanatri, Keichi Takahashi, Yutaro Kashiwa, Kohei Ichikawa, Hajimu Iida, Toward Automatic Parallelization: Detecting Parallelizable Loop using Large Language Modeling, Journal of Information Processing Systems, Status: Accepted and in print.
- Soratouch Pornmaneerattanatri, Keichi Takahashi, Yutaro Kashiwa, Kohei Ichikawa, Hajimu Iida, Automatic Parallelization with CodeT5+: A Model for Generating OpenMP Directives, 2024 International Workshop on Large Language Models (LLMs) and HPC, September 24, 2024.
- Soratouch Pornmaneerattanatri, Keichi Takahashi, Yutaro Kashiwa, Kohei Ichikawa, Hajimu Iida, Parallelizable Loop Detection using Pre-trained Transformer Models for Code Understanding, International Conference on Parallel and Distributed Computing: Applications and Technologies, pages 32-42, August 16-18, 2023.